

Introduction to Polypheny
Polypheny is a database management system (DBMS) that is designed to support the efficient processing of complex queries over large and heterogeneous datasets. As a polystore system, it uses highly optimized databases and utilizes them as execution engines. This not only enables the efficient processing of structured, semi-structured and unstructured data, but also ensures the efficient processing of mixed workloads.
Some key advantages of Polypheny are:
- Support a wide range of data types, data models, queries, and workloads
- Handle large amounts of heterogeneous data while maintaining good performance
- Support data integration from various sources
- Access the data through various industry-standard interfaces
Polypheny is a powerful and flexible DBMS that is well-suited for a wide range of data-intensive applications, including data analytics, machine learning and more. Furthermore, it is an extremely useful tool for data scientists.
Centralized Data Platform Access
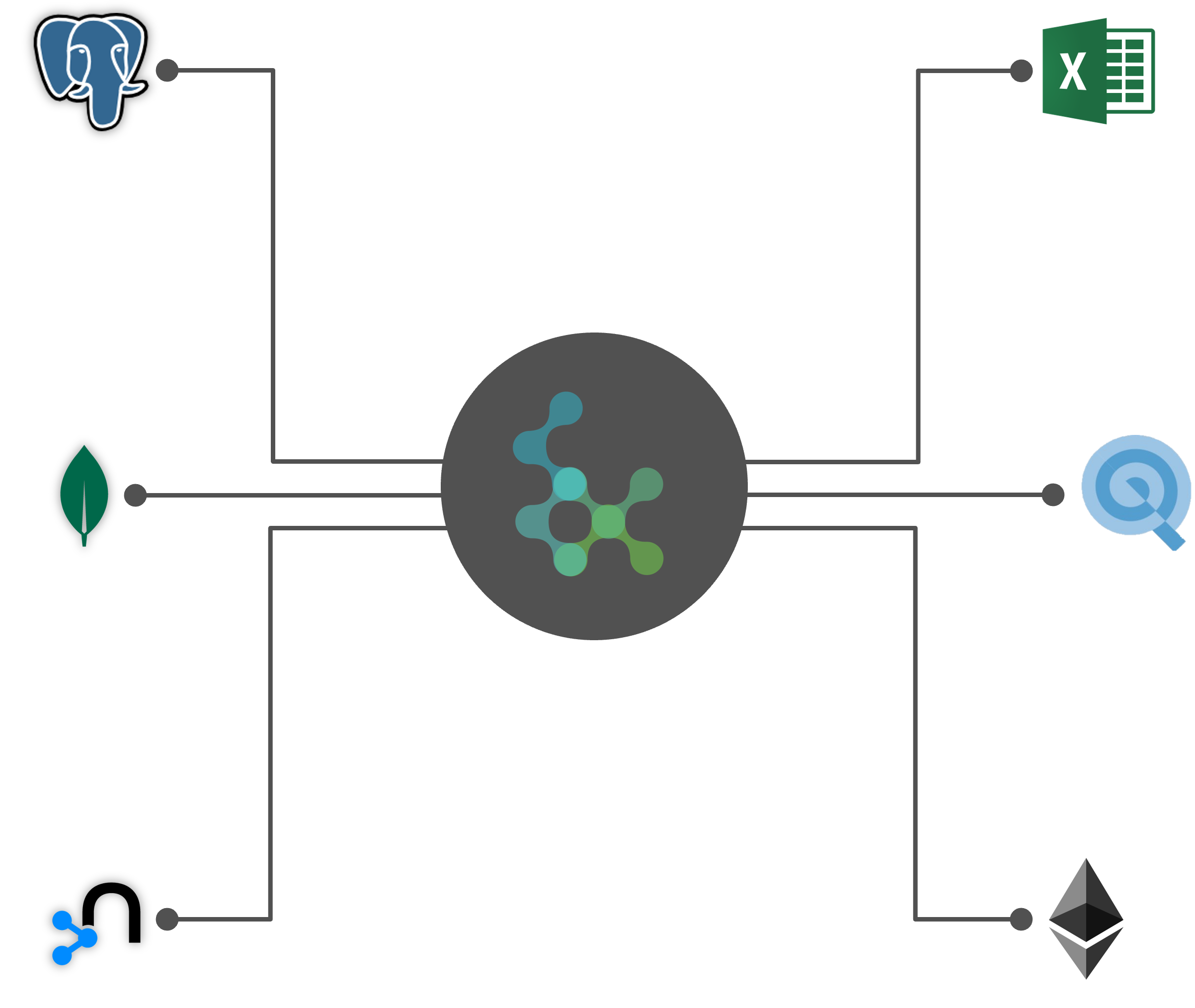
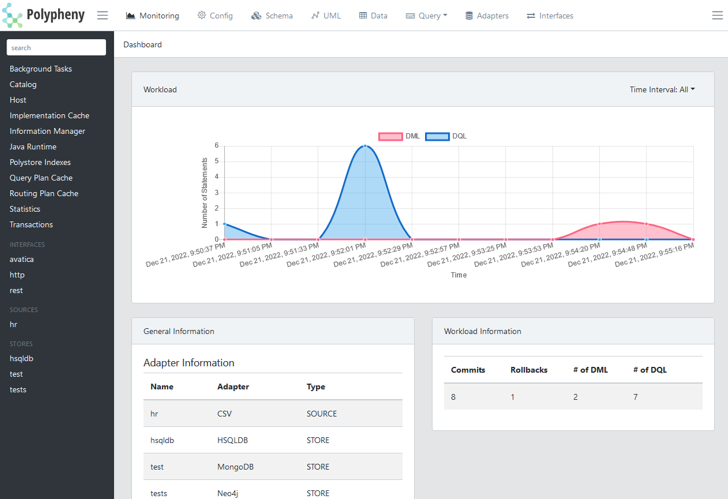
Intuitive and Powerful UI
Polpyheny comes with a powerful and easy-to-use browser-based user interface. This interface does not only allow the management and monitoring of the Polypheny system but also enables the management of the data and the schema and also provides additional methods for querying the data.
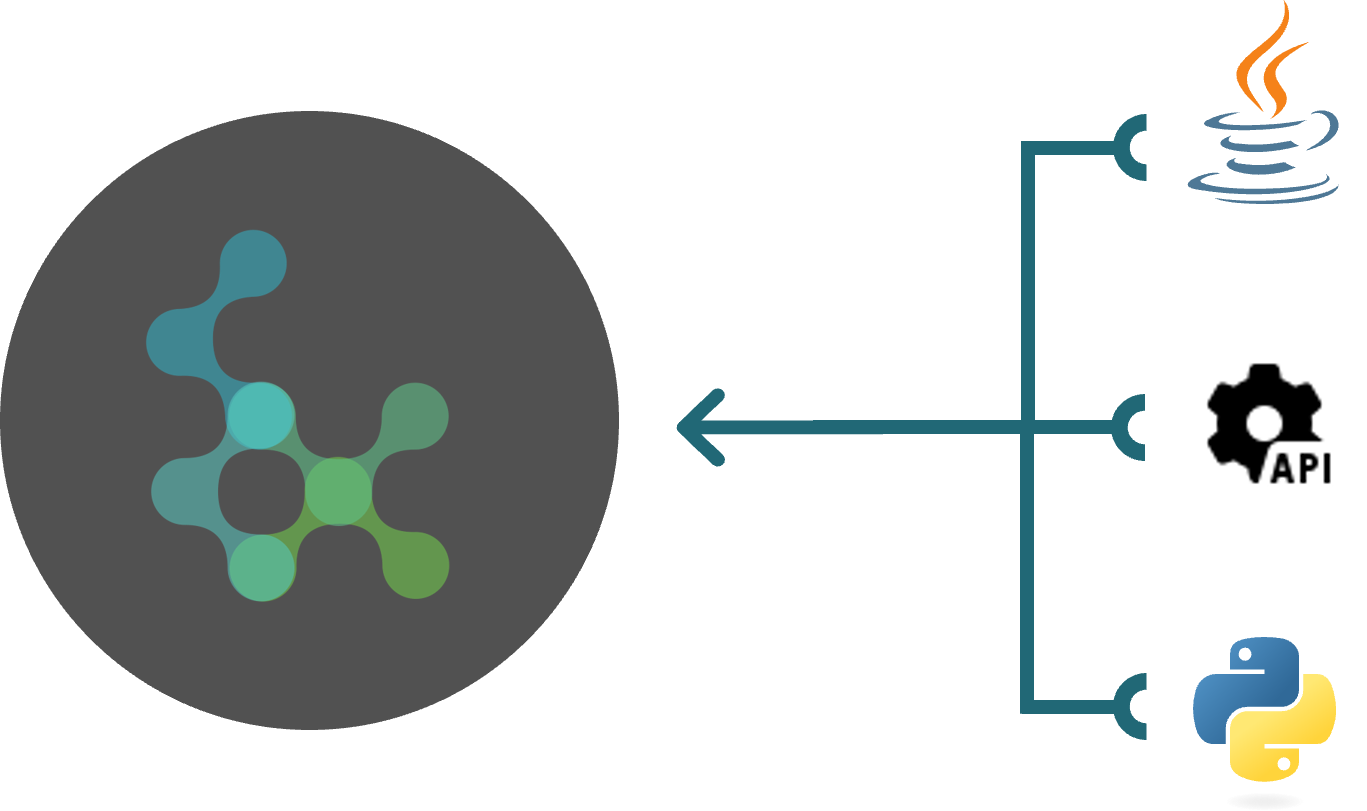
Various Connectors & Drivers
Polypheny can easily and conveniently integrate into various projects and environments using the provided drivers and connectors. This includes:
- JDBC
- RESTful API
- Python
- HTTP API
Multi-Model Data Management
Polpyheny is inherently built to support multiple data models including the relational, document, and graph data models. The native support for the three major data models makes Polypheny suitable for many application scenarios. The automatic and seamless mapping between the supported data models and the ability to execute cross-model queries allows for tighter integration of heterogeneous data from various sources. Using Polypheny allows harvesting the benefits of each data model.
Relational
The relational data model represents data as a collection of tables with a fixed set of columns. Relationships between data items within the same or another table can be expressed using foreign keys. The relational data model is a well-known and widely used data model suitable for many applications.


Document
The document data model is especially suited for storing loosely structured and unstructured data. The data is organized as collections of documents. Every document can have an arbitrary (deeply-nested) structure.
Graph
Graph data models are especially suited to encode relationship information. The data is organized as nodes connected by edges. Nodes and edges have labels and a set of arbitrary key-value pairs. Polypheny supports the powerful and versatile Label-Property-Graphs (LPG) model.

Query Languages
A core element of Polypheny’s versatility is to query data using multiple query languages. Every query language can be used to query the data, independent of the data model. If the data model of the query language does not match the accessed data model, Polypheny automatically applies a semantic preserving mapping between these data models.
The support for multiple data models not only allows easy integration into existing application scenarios but also provides an enormous amount of query techniques and approaches, making Polypheny suitable for a multitude of applications.
SQL
SQL is a widely used language and the industry standard for querying relational databases. The SQL dialect supported by Polypheny follows the SQL standard. The large set of supported query- and aggregation functions makes this an extremely powerful language for query Polypheny.
SELECT o_year,
SUM(
CASE WHEN nation = 'Switzerland'
THEN volume ELSE 0 END)
/ SUM(volume) AS mkt_share
FROM(
SELECT
EXTRACT(year FROM o_orderdate) AS o_year,
l_extendedprice * (1 - l_discount) AS volume,
n2.n_name AS nation
FROM orders, customer, nation n1, nation n2, region
WHERE AND o_custkey = c_custkey
AND c_nationkey = n1.n_nationkey
AND r_name = 'Basel'
AND s_nationkey = n2.n_nationkey
AND o_orderdate BETWEEN date '2020-06-03'
AND date '2020-08-03'
AND p_type = 'Wireless'
) AS all_nations
GROUP BY o_year
ORDER BY o_year
db.orders.aggregate([
{ $match:
{ "date":{
$gte: new ISODate( "2020-01-30" ),
}
},
{ $group:
{ _id: { $dateToString: {
format: "%Y-%m-%d", date: "$date" }
},
totalOrderValue: { $sum: {
$multiply: [ "$price", "$quantity" ] }
},
averageOrderQuantity: { $avg: "$quantity" }
}
},
{ $sort: { totalOrderValue: -1 } }
])
MongoQL
A powerful query language built for retrieving document-based data. The implementation in Polypheny closely follows the standard given by MongoDB version 5.0. The MongoDB Query Language is a widely adopted query language that, thanks to Polypheny’s cross-model capabilities, can also be used to query other data models.
Cypher
Cypher is a declarative graph query language for property graphs. It is widely used and has become the industry standard for querying graph databases. The implementation in Polypheny closely follows the openCypher standard.
CREATE (adam:User {name: 'Adam'}),
(pernilla:User {name: 'Pernilla'}),
(david:User {name: 'David'}),
(adam)-[:FRIEND]->(pernilla),
(pernilla)-[:FRIEND]->(david),
(david)-[:FRIEND]->(adam);
MATCH (n) RETURN n;
public.employee.empname == "Loki"
CQL
The Contextual Query Language is a formal language for representing queries to information retrieval systems. It is primarily used to query bibliographic catalogs and museum collection information. Polypheny’s CQL implementation makes some minor changes and adds many extensions to the CQL specifications.
Pig
The Pig query language was originally designed as an easy approach for writing programs that run on Apache Hadoop. However, it is also a powerful language for writing analytical query scripts in a structured fashion. Polypheny’s implementation uses a special adaption of the Apache Pig implementation but replaces the regularly used files with database entities.
A = LOAD 'employee';
B = FILTER A BY empname == 'Loki';
Supports the Databases You Love
Polypheny supports various well-known and highly optimized database systems for storing data. This inherently distributed architecture allows for easy horizontal scaling and thus, the processing of huge amounts of data.
Polypheny supports a wide range of data types, including integers, floating-point numbers, strings, and more. It also supports data updates and transactions, enabling Polypheny, to be used for a various use cases. This allows multiple users to update and query the data simultaneously without conflicting with each other.
The data storage in Polypheny is designed to be scalable, flexible, and efficient, allowing it to handle the demands of modern data-intensive applications.
Stores


Sources




Query Processing, Performance & Scalability
Polypheny includes a query optimizer and execution engine responsible for executing queries over the stored data. Polypheny excels with its ability to combine the advantages of highly optimized data stores and its ability to efficiently accommodate and process multiple data models.
The optimizer selects the most efficient execution plan for each query based on the data distribution and other factors. The execution engine executes the plan on the data store, if supported or in the execution engine, if not. If the data is replicated on multiple underlying data stores, the system picks the data store with the best characteristics for executing a (sub) query. The optimizer uses various techniques, such as cost-based optimization and rule-based optimization, to choose the most efficient execution plan for each query.
Polypheny also includes caching support, allowing it to store frequently used query plans in memory for faster access. This can significantly improve the performance of queries that access the same data multiple times.
The performance and scalability of Polypheny are designed to meet the demands of modern data-intensive applications. It is capable of efficiently processing complex queries over large datasets. Its inherently distributed architecture allows for seamless scaling and adaption to the demands of the particular use case.
Mapping and Cross-Model Queries
A key characteristic and unique feature of Polypheny is its ability to seamlessly map between different data models. This enables all data to be queried using all supported query languages – independent of the data model the query language is based on. Furthermore, Polypheny is also able to map data to all underlying data stores. This enables every data store to serve as storage and execution engine.
To clearly define schemas based on different data models, Polypheny uses the notion of “namespaces”. There can be an arbitrary number of namespaces. Every namespace has a unique name and is of a specific model type. Within a namespace, only schema objects of a certain data model can be used. For instance: in a relational namespace, there are tables, while in a graph namespace, there are nodes and edges.
These seamless mappings enable easy-to-write and extremely powerful cross-model queries. A query can also access multiple namespaces of different types. Since the available set of features depends on the query languages, this is especially handy for query languages supporting the semantics of joins. This allows to combine data represented according to different data models within one query. Since the mappings are designed to map the semantic concepts, such queries also “feel” natural and do not impose any restrictions on the set of features that can be used.
Use Cases and Applications
Polypheny is a powerful and flexible DBMS that is well-suited for a wide range of data-intensive applications. It has been built for scenarios that require the handling of heterogeneous data and mixed workloads. Some possible use cases and applications for Polypheny include:
-
Data Analytics: Polypheny enables the whole data lake to be queried in real-time. Its support for static data sources such as CSV or Excel files allows them to be processed without prior import. Allowing to always work with the latest data.
-
Machine Learning: Polypheny’s support for accommodating data represented according to different data models and the ability to query and combine this data makes it an excellent choice for machine learning application.
-
Data Integration: Polypheny allows data previously stored in disjunct databases to be maintained in one database system with no or only minimal changes to the applications. This allows to migrate schemas and leads to a tighter integration of data.
-
Multimedia Retrieval: Polypheny’s capabilities to natively handle multimedia data and the support for typical retrieval functions like nearest-neighbor search, make Polypheny an excellent choice for multimedia retrieval systems that require high performance for mixed retrieval and metadata workloads.
Its efficient query processing makes Polypheny a powerful and flexible choice for handling the demands of modern data-intensive workloads.