

Einführung
Polypheny ist ein Datenbankmanagementsystem (DBMS), das für die effiziente Verarbeitung komplexer Abfragen über grosse und heterogene Datenbestände konzipiert ist. Als Polystore-System verwendet es hochoptimierte Datenbanken und kombiniert deren stärken. Dies ermöglicht nicht nur die effiziente Verarbeitung von strukturierten, halbstrukturierten und unstrukturierten Daten, sondern gewährleistet auch die effiziente Verarbeitung gemischter Anfragelasten.
Einige der wichtigsten Vorteile von Polypheny sind:
- Unterstützung eines breiten Spektrums von Datentypen, Datenmodellen, Abfragen und Workloads
- Verarbeitung grosser Mengen heterogener Daten bei gleichbleibend guter Leistung
- Unterstützung der Datenintegration aus verschiedenen Quellen
- Zugriff auf die Daten über verschiedene gut etablierte und breit unterstütze Anfrageschnittstellen
Polypheny ist ein leistungsfähiges und flexibles DBMS, das sich für eine Vielzahl von datenintensiven Anwendungen eignet, darunter Datenanalyse, maschinelles Lernen und mehr. Darüber hinaus ist es ein äusserst nützliches Werkzeug für Datenwissenschaftler.
Zentraler Daten-Plattform Zugriff
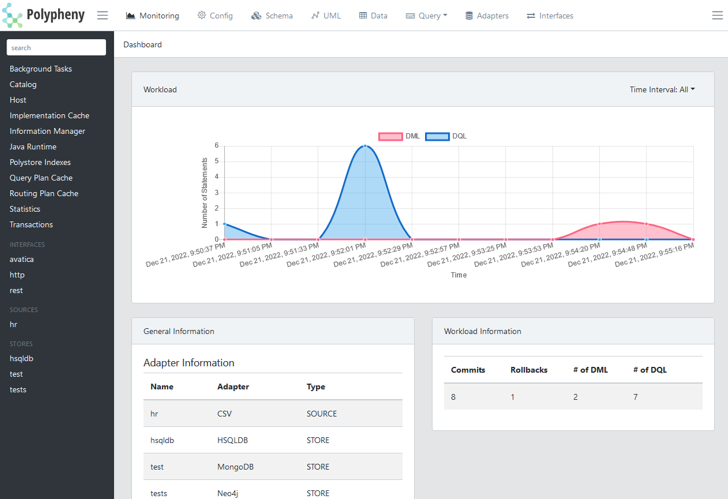
Intuitive und leistungsstarke Benutzeroberfläche
Polpyheny verfügt über eine leistungsfähiges und einfach zu bedienendes, Browser-basiertes Benutzerinterface. Dieses Interface ermöglicht nicht nur die Verwaltung und die Überwachung des Polypheny Systems, sondern ermöglicht auch die Verwaltung der Daten und des Schemas und bietet darüber hinaus zusätzliche Methoden zum Abfragen der Daten.
Vielseitige Konnektoren & Treiber
Polypheny lässt sich mit den bereitgestellten Treibern und Konnektoren einfach und bequem in verschiedene Projekte und Umgebungen integrieren. Dazu gehören:
- JDBC
- RESTful API
- Python
- HTTP-API
Multi-Model Daten Management
Polypheny ist von Grund auf für die Unterstützung mehrerer Datenmodelle konzipiert, darunter das relationale, das Dokumenten- und das Graph-Datenmodell. Die native Unterstützung für die drei wichtigsten Datenmodelle macht Polypheny für eine Vielzahl von Anwendungsszenarien geeignet. Das automatische und nahtlose Mapping zwischen den unterstützten Datenmodellen und die Möglichkeit, modellübergreifende Abfragen durchzuführen, ermöglicht eine engere Integration heterogener Daten aus verschiedenen Quellen. Mit Polypheny lassen sich die Vorteile der einzelnen Datenmodelle gewinnbringend kombinieren.
Relational
Das relationale Datenmodell repräsentiert Daten als eine Sammlung von Tabellen mit einem festen Satz von Spalten. Beziehungen zwischen Datenelementen innerhalb der gleichen oder einer anderen Tabelle können durch Fremdschlüssel ausgedrückt werden. Das relationale Datenmodell ist ein bekanntes und weit verbreitetes Datenmodell, das sich für viele Anwendungen eignet.


Document
Das Dokumentdatenmodell eignet sich besonders für die Speicherung lose strukturierter und unstrukturierter Daten. Die Daten werden als Sammlungen von Dokumenten organisiert. Jedes Dokument kann eine beliebige (tief verschachtelte) Struktur haben.
Graph
Graphische Datenmodelle sind besonders geeignet, um Beziehungsinformationen zu kodieren. Die Daten sind als Knoten organisiert, die durch Kanten verbunden sind. Knoten und Kanten haben Bezeichnungen und eine beliebige Anzahl von Schlüssel-Wert-Paaren. Polypheny unterstützt das leistungsfähige und vielseitige Label-Property-Graphs (LPG) Modell.

Abfragesprachen
Ein Kernelement der Vielseitigkeit welche Polypheny auszeichnet, ist die Abfrage von Daten mit mehreren Abfragesprachen. Jede Abfragesprache kann zur Abfrage aller Daten verwendet werden, unabhängig vom Datenmodell. Wenn das Datenmodell der Abfragesprache nicht mit dem Datenmodell übereinstimmt, auf das zugegriffen wird, wendet Polypheny automatisch ein semantikerhaltendes Mapping zwischen diesen Datenmodellen an.
Die Unterstützung mehrerer Datenmodelle ermöglicht nicht nur die einfache Integration in bestehende Anwendungsszenarien, sondern bietet auch eine enorme Anzahl von Abfragetechniken und -ansätzen, wodurch Polypheny für eine Vielzahl von Anwendungen geeignet ist.
SQL
SQL ist eine weit verbreitete Sprache und der Industriestandard für die Abfrage relationaler Datenbanken. Der von Polypheny unterstützte SQL-Dialekt folgt dem SQL-Standard. Die Vielzahl der unterstützten Abfrage- und Aggregationsfunktionen macht diese Sprache zu einer extrem leistungsfähigen Abfragesprache für Polypheny.
SELECT o_year,
SUM(
CASE WHEN nation = 'Switzerland'
THEN volume ELSE 0 END)
/ SUM(volume) AS mkt_share
FROM(
SELECT
EXTRACT(year FROM o_orderdate) AS o_year,
l_extendedprice * (1 - l_discount) AS volume,
n2.n_name AS nation
FROM orders, customer, nation n1, nation n2, region
WHERE AND o_custkey = c_custkey
AND c_nationkey = n1.n_nationkey
AND r_name = 'Basel'
AND s_nationkey = n2.n_nationkey
AND o_orderdate BETWEEN date '2020-06-03'
AND date '2020-08-03'
AND p_type = 'Wireless'
) AS all_nations
GROUP BY o_year
ORDER BY o_year
db.orders.aggregate([
{ $match:
{ "date":{
$gte: new ISODate( "2020-01-30" ),
}
},
{ $group:
{ _id: { $dateToString: {
format: "%Y-%m-%d", date: "$date" }
},
totalOrderValue: { $sum: {
$multiply: [ "$price", "$quantity" ] }
},
averageOrderQuantity: { $avg: "$quantity" }
}
},
{ $sort: { totalOrderValue: -1 } }
])
MongoQL
Eine leistungsstarke Abfragesprache für den Abruf von dokumentenbasierten Daten. Die Implementierung in Polypheny folgt eng dem Standard von MongoDB Version 5.0. Die MongoDB Query Language ist eine weit verbreitete Abfragesprache, die dank der modellübergreifenden Fähigkeiten von Polypheny auch für die Abfrage anderer Datenmodelle verwendet werden kann.
Cypher
Cypher ist eine deklarative Graphenabfragesprache für Eigenschaftsgraphen. Sie ist weit verbreitet und hat sich zum Industriestandard für die Abfrage von Graphdatenbanken entwickelt. Die Implementierung in Polypheny lehnt sich eng an den openCypher-Standard an.
CREATE (adam:User {name: 'Adam'}),
(pernilla:User {name: 'Pernilla'}),
(david:User {name: 'David'}),
(adam)-[:FRIEND]->(pernilla),
(pernilla)-[:FRIEND]->(david),
(david)-[:FRIEND]->(adam);
MATCH (n) RETURN n;
public.employee.empname == "Loki"
CQL
Die Contextual Query Language ist eine formale Sprache zur Darstellung von Abfragen an Information Retrieval Systeme. Sie wird hauptsächlich für die Abfrage von bibliografischen Katalogen und Sammlungsinformationen in Museen verwendet. Die CQL-Implementierung von Polypheny nimmt einige kleinere Änderungen vor und fügt den CQL-Spezifikationen zahlreiche Erweiterungen hinzu.
Pig
Die Abfragesprache Pig wurde ursprünglich als einfacher Ansatz zum Schreiben von Programmen konzipiert, die auf Apache Hadoop laufen. Sie ist jedoch auch eine leistungsstarke Sprache für das strukturierte Schreiben analytischer Abfrageskripte. Die Polypheny-Implementierung folgt der Apache Pig Referenzimplementierung, nimmt aber einige Anpassungen vor. Insbesondere werden Dateien durch Datenbankentitäten ersetzt.
A = LOAD 'employee';
B = FILTER A BY empname == 'Loki';
Unterstützt die Datenbanken die Du Liebst
Polypheny unterstützt verschiedene bekannte und hoch-optimierte Datenbanksysteme zur Speicherung von Daten. Diese inhärent verteilte Architektur ermöglicht eine einfache horizontale Skalierung und damit die Verarbeitung sehr grosser Datenmengen.
Polypheny unterstützt eine breite Palette von Datentypen, darunter Ganzzahlen, Fliesskommazahlen, Strings und mehr. Polypheny unterstützt auch Datenaktualisierungen und -transaktionen, wodurch es für eine Vielzahl von Anwendungsfällen genutzt werden kann. So können mehrere Benutzer die Daten gleichzeitig aktualisieren und abfragen, ohne einander zu behindern.
Die Datenspeicherung in Polypheny ist so konzipiert, dass sie skalierbar, flexibel und effizient ist und den Anforderungen moderner datenintensiver Anwendungen gerecht wird.
Stores


Sources




Query Processing, Performance & Skalierbarkeit
Polypheny enthält einen Abfrageoptimierer und eine Ausführungs-Engine, die für die Ausführung von Abfragen über die gespeicherten Daten verantwortlich ist. Polypheny zeichnet sich dadurch aus, dass es die Vorteile von hoch optimierten Datenspeichern und die Fähigkeit, mehrere Datenmodelle effizient unterzubringen und zu verarbeiten, miteinander verbindet.
Der Optimierer wählt auf der Grundlage der Datenverteilung und anderer Faktoren den effizientesten Ausführungsplan für jede Abfrage aus, und die Ausführungs-Engine führt den Plan auf dem Datenspeicher aus, sofern er unterstützt wird, oder in der Ausführungs-Engine, sofern dies nicht der Fall ist. Wenn die Daten auf mehrere zugrundeliegende Datenspeicher repliziert sind, wählt das System den Datenspeicher mit den besten Eigenschaften für die Ausführung einer (Teil-)Abfrage aus. Der Optimierer verwendet verschiedene Techniken wie die kostenbasierte Optimierung und die regelbasierte Optimierung, um den effizientesten Ausführungsplan für jede Abfrage zu wählen.
Polypheny unterstützt auch die Zwischenspeicherung (Caching) von häufig verwendeten Abfrageplänen im Speicher, um einen schnelleren Zugriff zu ermöglichen. Dies kann die Leistung von Abfragen, die mehrfach auf dieselben Daten zugreifen, erheblich verbessern.
Die Leistung und Skalierbarkeit von Polypheny ist auf die Anforderungen moderner datenintensiver Anwendungen ausgelegt. Es ist in der Lage, komplexe Abfragen über grosse Datenmengen effizient zu verarbeiten. Seine inhärent verteilte Architektur ermöglicht eine nahtlose Skalierung und Anpassung an die Anforderungen des jeweiligen Anwendungsfalls.
Mapping und modellübergreifende Abfragen
Ein wesentliches Merkmal und Alleinstellungsmerkmal von Polypheny ist die Fähigkeit, nahtlos zwischen verschiedenen Datenmodellen zu mappen. Dadurch können alle Daten mit allen unterstützten Abfragesprachen abgefragt werden - unabhängig vom Datenmodell, auf dem die Abfragesprache basiert. Darüber hinaus ist Polypheny auch in der Lage, Daten auf alle zugrundeliegenden Datenspeicher abzubilden. So kann jeder Datenspeicher als Speicher- und Ausführungsmaschine dienen.
Um Schemata, die auf unterschiedlichen Datenmodellen basieren, klar zu definieren, verwendet Polypheny das Konzept der “Namespaces”. Es kann eine beliebige Anzahl von Namespaces geben. Jeder Namespace hat einen eindeutigen Namen und gehört zu einem bestimmten Modelltyp. Innerhalb eines Namespaces können nur Schemaobjekte eines bestimmten Datenmodells verwendet werden. Ein Beispiel: In einem relationalen Namespace gibt es Tabellen, in einem Graph-Namespace Knoten und Kanten.
Diese nahtlosen Mappings ermöglichen einfach zu schreibende und extrem leistungsfähige modellübergreifende Abfragen. Eine Abfrage kann auch auf mehrere Namespaces unterschiedlicher Typen zugreifen. Da der verfügbare Funktionsumfang von den Abfragesprachen abhängt, ist dies besonders praktisch für Abfragesprachen, die die Semantik von Joins unterstützen. Dies ermöglicht es, in einer Abfrage Daten zu kombinieren, die auf Basis verschiedener Datenmodelle dargestellt werden. Da die Mappings darauf ausgelegt sind, die semantischen Konzepte abzubilden, “fühlen” sich solche Abfragen auch natürlich an und unterliegen keinen Beschränkungen hinsichtlich der verwendbaren Abfragefunktionen.
Anwendungsfälle
Polypheny ist ein leistungsfähiges und flexibles DBMS, das sich für eine Vielzahl von datenintensiven Anwendungen eignet. Es wurde für Szenarien entwickelt, die den Umgang mit heterogenen Daten und gemischten Arbeitsbelastungen erfordern. Einige mögliche Anwendungsfälle und Applikationen für Polypheny sind:
-
Datenanalyse: Polypheny ermöglicht die Abfrage des gesamten Data Lake in Echtzeit. Durch die Unterstützung von statischen Datenquellen wie CSV- oder Excel-Dateien können diese ohne vorherigen Import verarbeitet werden. Dies ermöglicht es, immer mit den aktuellsten Daten zu arbeiten.
-
Maschinelles Lernen: Die Unterstützung von Polypheny für die Aufnahme von Daten, die nach verschiedenen Datenmodellen dargestellt werden, und die Fähigkeit, diese Daten abzufragen und zu kombinieren, macht es zu einer ausgezeichneten Wahl für Anwendungen des maschinellen Lernens.
-
Datenintegration: Polypheny ermöglicht es, bisher in getrennten Datenbanken gespeicherte Daten in einem Datenbanksystem zu verwalten, und dies ohne oder mit nur minimalen Änderungen an den Anwendungen. Dies ermöglicht die Migration von Schemata und führt zu einer engeren Integration der Daten.
-
Multimedia Retrieval: Polypheny’s Fähigkeiten zur nativen Verarbeitung von Multimediadaten und die Unterstützung typischer Retrievalfunktionen wie die Nearest-Neighbor-Suche machen Polypheny zu einer ausgezeichneten Wahl für Multimedia-Retrieval-Systeme, die eine hohe Performance für gemischte Retrieval- und Metadaten-Workloads benötigen.
Die effiziente Abfrageverarbeitung macht Polypheny zu einer leistungsstarken und flexiblen Lösung für die Anforderungen moderner datenintensiver Workloads.